NLP¶
Word Representation¶
fMRI-imaging of the brain suggests that word embeddings are related to how the human brain encodes meaning 1
word2vec 2¶
无监督学习
Motivation¶
直接的文字表达信息稀疏,不足以提供文字单元间的关系,因此会造成需要更大量的数据来学习
one-hot representation 存在的问题:维数灾难和稀疏(sparse)会导致计算上的问题; 忽略了词之间的关系
低维特征在套用DL 更合适
基本思想¶
we have a large corpus of text
Every word in a fixed vocabulary is represented by a vector
Go through each position t in the text, which has a center word c and context (“outside”) words o
Use the similarity of the word vectors for c and o to calculate the probability of o given c (or vice versa)
Keep adjusting the word vectors to maximize this probability
模型¶
CBOW(Continuous Bag-of-Words)¶
通过上下文来预测中心词
CBOW smoothes over a lot of the distributional information (by treating an entire context as one observation). For the most part, this turns out to be a useful thing for smaller datasets .
训练¶
这个训练过程的参数规模非常巨大,一般来说,有Hierarchical Softmax、Negative Sampling等方式来解决。
Word pairs and “phases”
对高频词抽样
negative sampling:随机(跟概率有关)选择k个negative 单词, 仅更新positive 及 k 个 negative 词的权重;works better for frequent words and lower dimensional vectors
hierarchical softmax(Huffman Tree): tends to be better for infrequent words
GloVe¶
TODO: Some ideas from Glove paper have been shown to improve skip-gram (SG) model also (eg. sum both vectors)
GloVe(Global Vectors for Word Representation)是一个基于全局词频统计(count-based & overall statistics)的词表征工具,非神经网络方法,其得到的词向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)
Word2Vec 和 Glove 的对比¶
word2vec仍然是state-of-the-art的,相比之下GloVe略逊一筹(performance上差别不大?)
两个模型在并行化上有一些不同,即GloVe更容易并行化,所以对于较大的训练数据,GloVe更快。
评价¶
Intrinsic Evaluation(内部评测):
similarity task
analogy task
WordSim-353, SimLex-999, Word analogy task, Embedding visualization等。不仅要评测pair-wise的相似度,还考虑词向量用于推理的实际效果(Analogical Reasoning)
Extrinsic Evaluation(外部评测):
评估训练出的词向量在其它任务上的效果,即其通用性。(Task-specific)
其他直接方式
Evaluation of Word Vector Representations by Subspace Alignment (Tsvetkov et al.)
Evaluation methods for unsupervised word embeddings (Schnabel et al.)
NLG¶
turotial:
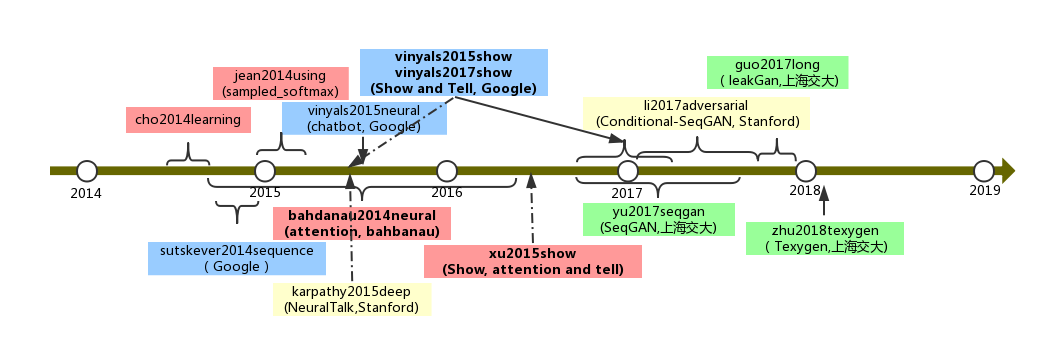
Seq2Seq¶
cho2014learning 4 提出 Encoder-Decoder 结构, 以及 GRU 这个 RNN 结构。
Cho etl 4 的模型结构中,语义向量c(整个句子的)需要作用到每个时刻t, 而在sutskever2014sequence 5 中Encoder 最后输出的中间语义只作用于 Decoder 的第一个时刻,这样子模型理解起来更容易一些。 另外,作者使用了一个trick: 将源句子顺序颠倒后再输入 Encoder 中,使得性能得到提升。 Google 的机器对话 6 用的就是这个 seq2seq 模型。 文中参数量计算过程
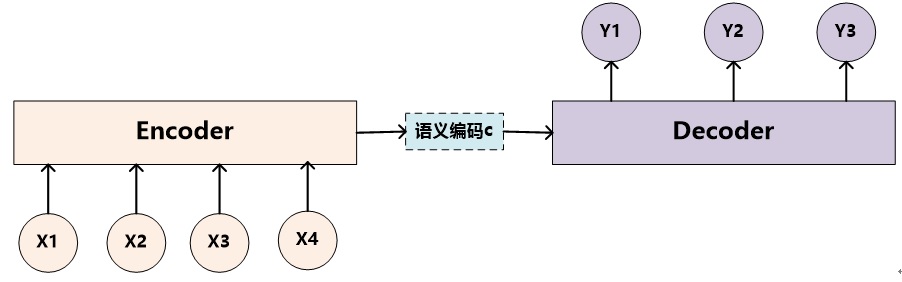
基础seq2seq模型¶
Cho etl 4 的 decoder 中,每次预测下一个词都会用到中间语义c,而这个c主要就是最后一个时刻的隐藏状态。bahdanau2014neural 7 提出了attention模型(详情查看 Attention),在Decoder进行预测的时候,Encoder 中每个时刻的隐藏状态都被利用上了。这样子,Encoder 就能利用多个语义信息(隐藏状态)来表达整个句子的信息了。此外,Encoder用的是双端的 GRU 深度学习中的注意力机制(2017版)
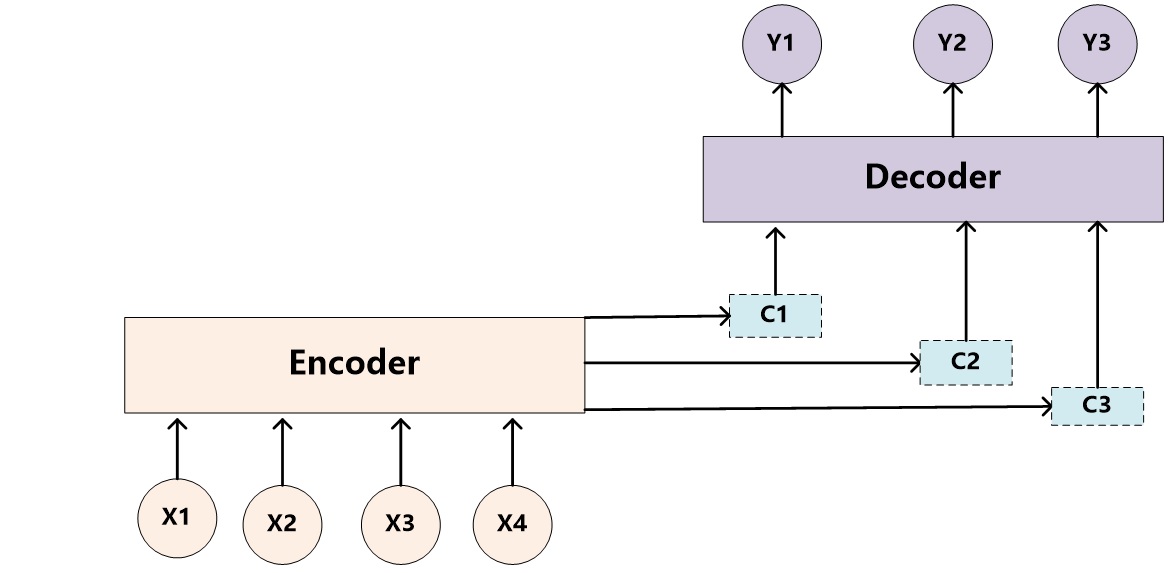
attention 机制的 seq2seq模型¶
jean2014using 8 提出sampled_softmax 用于解决词表太大的问题
Training tricks¶
- teacher forcing
At some probability, we use the current target word as the decoder’s next input rather than using the decoder’s current guess. This technique acts as training wheels for the decoder, aiding in more efficient training. However, teacher forcing can lead to model instability during inference , as the decoder may not have a sufficient chance to truly craft its own output sequences during training. Thus, we must be mindful of how we are setting the teacher_forcing_ratio, and not be fooled by fast convergence.
- gradient clipping
This is a commonly used technique for countering the “exploding gradient” problem. In essence, by clipping or thresholding gradients to a maximum value, we prevent the gradients from growing exponentially and either overflow (NaN), or overshoot steep cliffs in the cost function.
loss 函数average 到 batch就可,不用到timestep, which plays down the errors made on short sentences .
Decoding¶
ancestral/random sampling
greedy decoding/search (1-best)
beam-search decoding (n-best)
门特卡罗搜索?
缺点¶
只能计算前缀部分的概率(改进可用recursive neural network)
使用最大似然估计模型参数
第一个缺点使seq2seq 不容易理解文本 ,因为AI-requires being able to understand bigger things from knowing about small parts.
第二个缺点使seq2seq的 对话不像真实的对话 ,只考虑当前对话最大似然忽略了对话对未来的影响:
- 容易出现“I don’t know”(因为其概率最大,其他方向的相互抵消);
- 对话重复(不考虑上下文的关系)等问题。
针对第二个缺点,我们了解到概率最高的输出不一定等于好的输出,好的对话需要考虑长久的信息。可以引入强化学习,人为设计相关的reward让机器更好地学习。
Attention 机制¶
详情查看 Attention
术语¶
Copus: 语料库
stemming: 词干化
Word Embedding: 词嵌入
Distributed Representation
Distributional Representation
Information Retrieval (IR)
Natural Language Processing (NLP)
Natural Language Inference(NLI)
Out of Vacabulary(OOV)
References¶
- 1
Mitchell T M, Shinkareva S V, Carlson A, et al. Predicting human brain activity associated with the meanings of nouns[J] . science, 2008, 320(5880): 1191-1195.
- 2
Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J] . arXiv preprint arXiv:1301.3781, 2013.
- 3
Mihalcea R, Tarau P. Textrank: Bringing order into text[C] //Proceedings of the 2004 conference on empirical methods in natural language processing. 2004.
- 4(1,2,3)
Cho K, Van Merriënboer B, Gulcehre C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation[J] . arXiv preprint arXiv:1406.1078, 2014.
- 5
Sutskever I, Vinyals O, Le Q V. Sequence to sequence learning with neural networks[J] . Advances in neural information processing systems, 2014: 3104-3112.
- 6
Vinyals O, Le Q. A neural conversational model[J] . arXiv preprint arXiv:1506.05869, 2015.
- 7
Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J] . arXiv preprint arXiv:1409.0473, 2014.
- 8
Jean S, Cho K, Memisevic R, et al. On using very large target vocabulary for neural machine translation[J] . arXiv preprint arXiv:1412.2007, 2014.