编程相关¶
编程相关
规范文档¶
C++:
函数:首字母大写
变量:全部小写,中间用_连接
运算符左右空一格
指针靠近数据类型
python: (未做特别声明均同上)
缩近两格
表明 __author__ = ‘XXX’
文档开头说明用连续的“# ”注释,末行“========”
系统 import 和 第三方 import 隔一行
函数说明在 def 下方的 “”” “”” 之,包含Args、Returns,其内容包含名称、数据结构、数据类型、shape等
代码块说明在其上方,用“# ”注释
关于不同编程语言¶
先了解一些基本概念
- Program Errors
trapped errors: 导致程序终止执行。如除0,Java中数组越界访问
untrapped errors: 出错后继续执行,但可能出现任意行为。如C里的缓冲区溢出、Jump到错误地址
- Forbidden Behaviours
语言设计时,可以定义一组forbidden behaviors. 它必须包括所有untrapped errors, 但可能包含trapped errors.
- Well behaved、ill behaved
well behaved: 如果程序执行不可能出现forbidden behaviors, 则为well behaved。
ill behaved: 否则为ill behaved
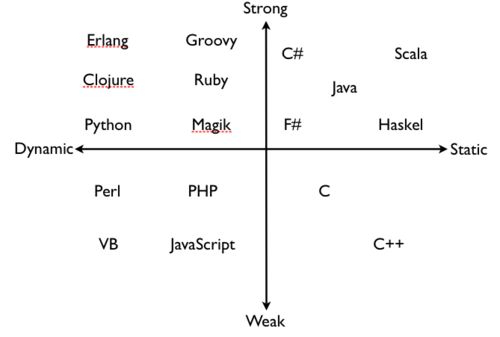
有了上面的概念,再讨论强、弱类型,静态、动态类型
- 强、弱类型
强类型(strongly typed): 如果一种语言的所有程序都是well behaved——即不可能出现forbidden behaviors,则该语言为strongly typed。
弱类型(weakly typed): 否则为weakly typed。比如C语言的缓冲区溢出,属于trapped errors,即属于forbidden behaviors..故C是弱类型,弱类型语言,类型检查更不严格,如偏向于容忍隐式类型转换。譬如说C语言的int可以变成double。 这样的结果是:容易产生forbidden behaviours,所以是弱类型的
- 动态、静态类型
- 静态类型(statically): 如果在 编译 时拒绝ill behaved程序,则是statically typed;静态类型可以分为两种:
显式类型(explicitly typed): 类型是语言语法的一部分;
隐式类型(implicity typed): 类型通过编译时推导,比如ML和Haskell
动态类型(dynamiclly): 如果在 运行 时拒绝ill behaviors, 则是dynamiclly typed。
小技巧
Dynamic compiled and dynamically typed don’t have much to do with each other. Typing is part of the language syntax, while the compilation strategy is part of the implementation of the language .
- Dynamic typing
means that you don’t necessarily have to declare the type when you declare a variable and that conversion between types happens automatically in most cases.
- Dynamic compiling
means that the language is compiled to machine code while the program is being executed, not before. This allows, for example, just-in-time optimization - the code is optimized while the application is running.
一些例子
编码¶
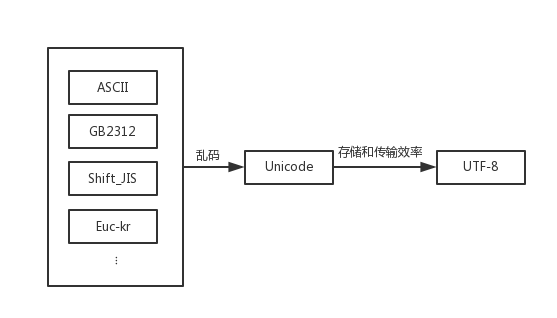
- ASCII码
用 1个字节 (8bit, 0-255)中的127个字母表示大小写字母,数字和一些符号。主要用来表示现代英语和西欧语言。
当计算机普及到各国时,这种编码无法涵盖更多别国字符,所以各国制定了各国的标准,中国制定了GB2312,日本制定了Shift_JIS,韩国制定了Euc-kr… 因此,出现了乱码问题。为了统一,Unicode诞生了。
- Unicode
把所有语言都统一到一套编码(通常是2个字节)里。
在计算机内存中,统一使用Unicode编码。
解决了乱码问题,但是存储和传输效率低下的问题又来了: ASCII编码是1个字节,而Unicode编码通常是2个字节,表示一个英文字母一个字节就够了,但是Unicode却不得不用两个字节来表示(另一个字节补0)。
- UTF-8
把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。
换行符¶
linux 下的换行符为’n’(LF), windows 下的换行符为 ‘rn’ (CR LF), 所以不同系统处理其他系统生成的文本会出现问题
在python中,
如果不是txt文件, 读写文件时通过设置 ‘rb’/’wb’ 参数避免这个问题。(二进制读写,不会有换行问题。)
如果需要明文内容
Python2用 ‘rU’ 来读取,即U通用换行模式(Universal new line mode)—— 该模式会把所有的换行符(r n rn)替换为n。只支持读入。
Python3不推荐用 ‘rU’模式!可通过open函数的newline参数来控制Universal new line mode
读取 时,不指定newline,则默认开启Universal new line mode;
写入 时,不指定newline,则换行符为各系统默认的换行符; 指定为newline=’n’,则都替换为n(相当于Universal new line mode);
不论读或者写时,newline=’‘都表示不转换。
当前工作记录¶
- roi_pooling_layer 的编译
编译时找不到nvcc: /usr/local/cuda/bin 未添加到环境变量
基于cpu 的编译通过,但在调用时出错 “undefined symbol”: 可能原因有两个
gcc 版本不一致,详情参考 tensorflow 的 Add an new op 章节 (只有版本不符时需要做此改动, 否则反而会编译不通过)
GPU 部分在CPU 时不应该实现,应加入判定条件,使其在条件不符时排除;GPU部分的头文件未导入
cpu 和 GPU 结果不同:CPU 和 GPU 的实现不同, 应该用 work_sharder
作为独立代码编译时,要注意.cc 与 .cu.cc 函数的连接,通过.h 文件实现函数共享会报错,可能是编译方法的问题。在没有解决编译问题前,可以通过将声明放到 .cc 中解决。
注:仅cpu 编译时,先将 CUDA 路径从环境变量注释掉,然后将 make.sh 中 CUDA_PATH 改成错的,然后编译
- 下一步
register float double 是否有区别
static_cast<int> 是否造成区别
GPU 部分代码的区别
是否可以以 user_op 加入
TODO¶
静/动态编译和使用静/动态库是一个概念吗?